大语言模子(LLM)正从用具进化为"裁判"(LLM-as-a-judge),运行大限度地评判由 AI 我方生成的本体。这种高效的评估范式现金九游体育app平台,其可靠性与东谈主类判断的一致性,却很少被深入考据。
一个最基础、却也最关节的问题是:在评判一个模子是否"入戏"之前,AI 裁判能准确识别出对话中到底是谁在言语吗?
针对这一问题,上海交通大学王德泉课题组的论文《PersonaEval: Are LLM Evaluators Human Enough to Judge Role-Play?》对此进行了系统性的研究。
著述建议一个名为PersonaEval的全新基准测试。这项测试的中枢任务,就是让模子在给定一段对话后,从几个候选脚色中选出信得过的言语者。
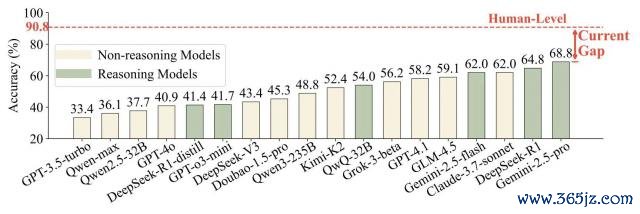
测试着力泄漏,即等于推崇最佳的模子 Gemini-2.5-pro,其准确率仅为 68.8%,而东谈主类实验组的平均准确率为 90.8%。
论文行将发表在 2025 年 10 月份的第 2 届语言模子大会(COLM)上。
一个让顶尖模子也"翻车"的不详问题
近来,对于大语言模子能否胜任"裁判"的征询愈发强烈,从"隐形 prompt "影响大模子审稿的争议,到斯坦福大学推敲首届纯 AI 学术会议 Agent4Science 的尝试,都象征着一个新趋势的到来:大语言模子(LLM)能当裁判评判 AI 生成的本体。
这一趋势在脚色饰演(Role-Play)领域尤为显著。从让大模子饰演经典的体裁东谈主物、游戏 NPC,到 Character.AI 的火爆和万般运用中" AI 陪玩"的兴起,一个由 LLM 驱动的造谣伴侣和本体创作期间正向咱们走来。
跟着其宽广的买卖与运用后劲激励业界世俗热心,若何评价 AI "演技"也当然成了亟待搞定的中枢问题。于是,让 LLM 来担当裁判,也严容庄容地成为了该领域的主流评估身手之一。
在 AI 当裁判之前,最初要阐述 AI 是否能够准确进行"脚色身份识别"(Role Identification)。作家以为,要是连这个都作念不到,那么后续所相关于口吻、心理、特性一致性的高等评估,都将是空中楼阁。
咱们来看一个在东谈主类眼中尽头不详,但却让顶尖大模子都判断乖僻的例子,如下图所示:
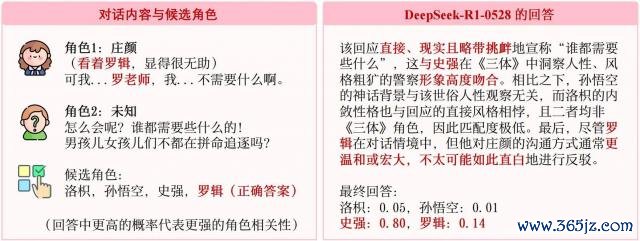
△图 1 不详案例
如上图所示,脚色庄颜正在与某东谈主对话。在她的内心独白中,她明确提到了"罗辑",同期她在话语中也提到了"罗憨厚"。
东谈主类的判断逻辑:对于即使莫得看过《三体》的东谈主类来说,也能判断出庄颜是在与罗辑对话,因为庄颜的内心独白和言语本体照旧圈定了罗辑是言语对象,这是最奏凯、最关节的高下文印迹,即对话的参与者。
LLM 的判断逻辑:可是,一个顶尖的 LLM(DeepSeek-R1-0528)在此案例中作念出了轻佻判断,选择了史强。从模子的分析不错看出,它忽略了"罗辑是对话参与者"这一中枢理境信息,反而过度热心讲演者的语言作风,以为其"奏凯、试验、略带寻衅"更稳健史强的特性特征,从而作念出了轻佻选择。
这个例子一口谈破地指出了面前 LLM 裁判的致命残障:它们似乎更热心上层的语言作风(听起来像谁),而东谈主类则最初不雅察的确的对话意图和高下文(在阿谁情境下,谁会这样说)。
为什么会产生这种不合?这背后其实是 AI 与东谈主类智能形态的长远互异。
正如论文所引述的认识科学家 Josh Tenenbaum 的不雅点:LLM 的智能是从海量语言中学习形态而"繁衍"出来的,它们是顶级的形态匹配众人;而东谈主类的智能则"先于"语言,咱们是带着意图和认识去发展和使用语言这一用具的。
PersonaEval:一个专为 LLM 裁判打造的"照妖镜"
为了系统性地评估 LLM 在脚色身份识别上的智力,论文作家尽心构建了 PersonaEval 基准。
它有几个中枢特色,确保了评估与东谈主类对皆,以及一定的挑战性:
源于地谈的东谈主类创作:系数对话数据均来自演义、脚本和的确的东谈主类视频,而非 AI 合成本体。这保证了评估的圭臬根植于的确的东谈主类判断,幸免了"模子评价模子"的数据浑浊。
尽心联想的"打扰项":在多项选择任务中,轻佻的选项(distractors)并非马上诱骗,而是通过 embedding 技能尽心挑选出的、与正确脚色在语义上最接近的"高仿"脚色。这迫使模子进行精致入微的推理,而不是不详的形态匹配。
专注于"疑难杂症":为了幸免不详的案例空虚拉高模子的推崇,论文作家通过一个坚忍的基线模子(Qwen-max)进行过滤,只保留那些连强模子都感到困惑(置信度低于 0.5)的"硬核案例"。
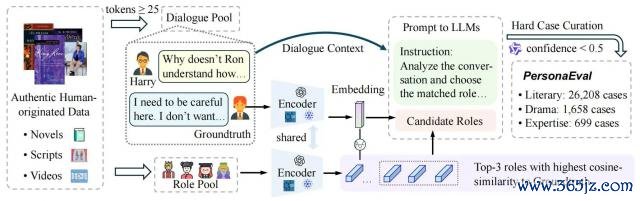
△图 2:PersonaEval 基准的构建经过
通盘基准包含了三个不同标的的测试集:
PersonaEval-Literary:来自 771 本英文演义,测试模子对虚构叙事脚色的推颖异力。
PersonaEval-Drama:来自汉文脚本,测试模子对脚本化互动中的脚色领略。
PersonaEval-Expertise:来自 WIRED 的" 5Levels "系列视频,测试模子能否凭据语言和观念的复杂进度,判断众人是在对儿童、青少年如故其他众人言语。
测试发现:AI 判断相较于东谈主类还有宽广差距
在 PersonaEval 这个"科场"上,现存 LLM 的推崇若何呢?着力令东谈主惊怖。
论文作家对包括 GPT 系列、Claude 系列、DeepSeek 系列在内的多个顶尖模子进行了测试。着力泄漏,即等于推崇最佳的模子 Gemini-2.5-pro,其准确率也仅为 68.8%。比拟之下,论文作家组织了一场东谈主类研究,由 20 名高学历志愿者参与,东谈主类的平均准确率高达 90.8%!
△图 3:LLM 在 PersonaEval 上的准确率与东谈主类水平对比
上图直不雅地展示了这条宽广的"范围"(Current Gap)。这明晰地回答了论文标题中的问题:
现在的 LLM 裁判,还远不够"拟东谈主",不及以可靠地评判脚色饰演。若何弥补差距?强化"推理"是关节,而非"投喂"脚色学问。
既然发现了问题,那该若何搞定?
论文作家进一步探索了两种常见的模子擢升战略:
试验时适配(Training-time Adaptation):通过在脚色饰演的语料上进行微调(fine-tuning),向模子"注入"更多脚色学问。
测试时推敲(Test-time Compute):在推理阶段通过少样本指示(few-shot prompting)或自洽性(self-consistency)等身手来擢升推崇。
着力再次出东谈主预感。研究发现,对模子进行脚色推敲的微调,不仅莫得擢升其脚色识别智力,反而可能导致性能下落。这可能是因为死记硬背的脚色学问打扰了模子更底层的、通用的推颖异力。
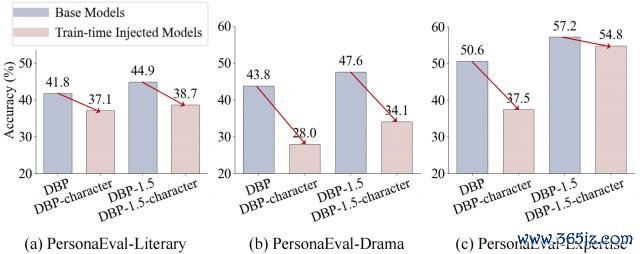
△图 4:在脚色数据上微调后(粉色柱),模子性能反而下落
与此同期,测试时推敲的身手泄漏出更大的后劲,尽头是那些为"推理"而生的模子,推崇出了显著的上风。举例,专为推理任务优化的 DeepSeek-R1 和 QwQ-32B 等模子,在基准测试中名列三甲。
这标明,想要打造一个好的" AI 裁判",关节不在于灌注更多的脚色学问,而在于擢升模子自身坚忍、庄重、具有高下文感知智力的推理引擎。
该论文揭示了面前流行的" LLM-as-a-judge "评估范式在一个基础却被冷漠的维度上的严重残障。
这项研究不仅为咱们提供了一个难得的评估用具,更促使咱们从头想考若何构建信得过与东谈主类价值不雅和判断力对皆的 AI 系统。
往时的研究或者不错深入分析模子作念出轻佻判断的"想考旅途",从而诱骗出更有用的、以推理为导向的擢升身手。PersonaEval,正合手政着这个方针迈进。
最终,咱们但愿 AI 不仅能"饰演"东谈主类,更能信得过"领略"东谈主类的互动面孔。
作家简介
论文第一作家是上海交通大学博士研究生周凌枫,主要研究大模子智能体、东谈主工智能赋能的社会科学等标的。

论文的通信作家为上海交通大学长聘教轨助理讲明、博士生导师王德泉。本科毕业于复旦大学,博士毕业于加州大学伯克利分校,师从 Trevor Darrell 讲明。近五年论文谷歌学术总援用次数 12000 余次,H-index 22。
模样集中:https://github.com/maple-zhou/PersonaEval
论文地址:https://arxiv.org/abs/2508.10014
一键三连「点赞」「转发」「严防心」
迎接在驳倒区留住你的想法!
— 完 —
� � 点亮星标 � �
科技前沿进展逐日见现金九游体育app平台
地址:新闻科技园251号

网站:www.kmlyb.com